在Seq2Seq與Transformer的章節中,如果你有跟著我們的內容進行訓練,你可能會發現:欸?怎麼訓練一個週期的時間都需要用到1小時呢?而我們花費這麼多時間訓練出來的結果,好像也沒有這些頂尖商業模型的效果來得好。那麼,我為什麼要自己訓練,而不是直接使用這些商業模型呢?答案其實很簡單,大多數的AI工作者並不會使用完全由自己訓練的模型進行工作。
第一點,我們並沒有充足的資料讓模型進行良好的學習。第二點,即便我們有足夠的資料,我們也缺乏足夠的硬體來訓練對應資料集和參數量的模型。因此,對於AI工作者而言,自行訓練模型往往不是最佳解答。那麼我們究竟該如何處理這些模型呢?今天我就是來告訴在AI領域中另一個重要概念遷移式學習(Transfer Learning)與預訓練模型(Pre-trained Model)
假設你今天是一個從事醫療領域的AI工作者,而你收到的指令是需要訓練一個英文病例報告摘要的模型。由於手頭上可用來訓練的資料數量有限,無論你如何訓練或修改Transformer,都無法訓練出理想的摘要模型。
這時你想到你曾在iThome上讀過austin70915的一篇文章,該文章講述了使用英文新聞進行訓練的文本摘要模型,而恰巧這個模型架構是你想要的Transformer模型,更幸運的是這位作者將權重開源出來了。於是你找到austin70915的GitHub帳號,將完整的模型架構與權重下載,並將手頭上的英文病例報告與對應的摘要文本作為訓練資料,在原始的模型上進行微調 (Fine-tuning)的動作,藉此讓模型的相關權重可以進行調整,使其從新聞的方向轉向醫療的方向。
這時問題來了這樣將Transformer以英文新聞摘要為基礎進行訓練,效果是否會比只使用英文醫療報告摘要資料來得更好呢?答案是肯定的,因為這個模型已經具備一定的摘要能力。即便換了一個領域,我們只需通過少量的資料來微調模型,因此這種既可以省下先前訓練Transformer的時間,還能提升模型的性能的方式,就叫做遷移式學習(Transfer Learning)。
預訓練模型(Pre-trained Model)是一種遷移學習的應用。這類模型在訓練時不僅限於單一方向,而是廣泛地多方面訓練,這意味著該模型的目標是達成通用性功能,例如同一個模型能進行翻譯、摘要、生成等不同操作。之所以能做到這點,是因為這些模型在大型資料集上進行了大量訓練,掌握了大量數據特徵,並能應對多種應用場景。但是這些模型通常具備數億甚至更多的參數量,因此訓練這些模型所耗費的資源極為龐大,通常只有頂尖的企業能做到這類型的訓練與開發。
打個比方預訓練模型就像是經過廣泛學習的專家,他們掌握了很多不同領域的知識,當遇到新的問題時,能夠基於這些已掌握的知識,快速理解並應對新的挑戰。因此使用預訓練模型有兩個主要目的,第一點是透過使用已經學習大量知識的模型,企業或研究機構可以省去大量的初期訓練時間,直接在預訓練模型基礎上進行應用開發。而第二點是預訓練模型可以更快速有效地應對各種任務,因為它已經學會如何處理大量通用的特徵,從而在少量的新資料上也能產生較好的結果。
而整個預訓練模型的過程包括預訓練階段和微調階段。在預訓練階段,大型模型架構(源模型)通常會由頂尖的科學家和技術團隊設計,並在龐大的資料集(源資料)上進行訓練。這個過程中,模型會學習大量通用的特徵,例如語言模型會學習到詞彙之間的關聯性、句子結構,圖像模型則會學習到物體的形狀、顏色和紋理等信息。
而在微調階段時我們通常會使用一個特定領域的小型資料集(目標資料),對預訓練模型進行微調,以適應具體任務需求。這個微調過程不需要像預訓練時那麼多的計算資源,因為大部分的學習已經在預訓練階段完成,微調只需要對部分權重進行調整,來適應新的目標資料。在訓練微調階段,我們的目標資料由於量少,可能會導致模型無法很好地調整其新方向。因此通常在開源預訓練模型後,會將其線性分類器的權重初始化,讓新資料來重新調整這個線性分類器的權重,以更好地將資料融合到模型中。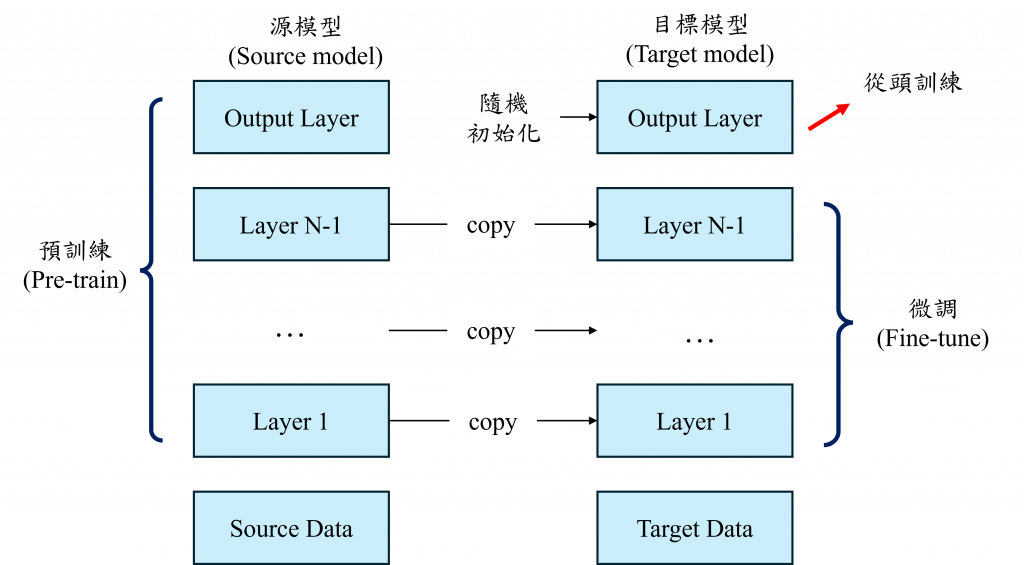
儘管預訓練模型帶來了許多便利,但其也面臨一些挑戰。由於模型架構已經是別人設定好的,我們想要對其架構進行修改時會遇到一定的難度。通常我們在修改模型架構時只能調整後續幾層的線性分類器,以免影響原始模型的權重。而且模型的資料集可能不包含我們當前任務所需的資訊。例如,該模型可能沒有訓練過文本摘要的任務,但我們卻用它來進行文本摘要,這樣會導致效果較差。因此在使用預訓練模型前,我們需要了解其架構與相關的論文,才能更好地理解並利用它。
而在微調上也有很多不同的應用,例如我們知道在Transformer的Q、K、V很重要,因此我們可以選擇凍結(Freeze)這些層以外的權重,讓模型在反向傳播時不會影響到其餘層的權重,來加速模型的訓練。或者,我們也可以選擇凍結所有線性分類器權重以外的層,讓模型只專注於能夠線性分類的結果。諸如此類的方式很多,大多數的目的就是為了減少記憶體的消耗並增加模型的效能。因此對於預訓練模型的優化與改動則非常依賴我們對於該模型架構的理解程度與經驗。當然就算不懂直接進行微調大多也能比自己訓練的模型還要來的好
簡單來說預訓練模型的出現讓我們能方便地使用他人已訓練好的模型來處理自己的資料。我們不必再花時間設計模型的架構,也不需特別考慮模型的前向傳播,只需要知道如何進行訓練就好。不過其實你現在應該已經瞭解了預訓練模型是如何訓練的,因為我在前面的章節中的程式碼,都是採用了Hugging Face公司的預訓練模型架構進行設計,因此在後續的幾天中我們也可以使用Trainer進行訓練。而當你理解了前面20天的內容後,會發現你對這些預訓練模型的架構及設計方式已經有了更深入的了解,這樣子你就能夠更好的對其架構進行改動與優化了~


 iThome鐵人賽
iThome鐵人賽